
บทที่ 5 : 5.3ความสัมพันธ์ในฐานข้อมูล
๕.๔ ประเภทโครงสร้างของฐานข้อมูล (Types of Database Structures)
(ในบริบทของระบบสารสนเทศภูมิศาสตร์ – GIS)
🔎 แนวคิดเบื้องต้น
ในการออกแบบระบบฐานข้อมูล โครงสร้างข้อมูล (Data Structure) เป็นองค์ประกอบสำคัญที่ช่วยให้สามารถจัดเก็บ เข้าถึง และวิเคราะห์ข้อมูลได้อย่างมีประสิทธิภาพ โดยเฉพาะในงานที่มีข้อมูลจำนวนมากและซับซ้อน เช่น ระบบสารสนเทศภูมิศาสตร์ (Geographic Information System: GIS) ซึ่งต้องจัดการทั้ง ข้อมูลเชิงพื้นที่ (Spatial Data) และ ข้อมูลเชิงคุณลักษณะ (Attribute Data)
ปัจจุบัน โครงสร้างฐานข้อมูลที่ใช้อยู่ทั่วไปแบ่งออกเป็น 3 รูปแบบหลัก ได้แก่:
๑. ฐานข้อมูลแบบลำดับขั้น (Hierarchical Database)
- โครงสร้างเป็นแบบ ต้นไม้ (Tree Structure) มีความสัมพันธ์ หนึ่งต่อกลุ่ม (1:N)
- ข้อมูลจัดเป็นลำดับชั้น เช่น จังหวัด → อำเภอ → ตำบล → หมู่บ้าน
- ข้อดี: เข้าถึงข้อมูลแนวดิ่งได้เร็ว
- ข้อจำกัด: ไม่ยืดหยุ่นในการเชื่อมโยงข้ามลำดับ เช่น การค้นข้อมูลจากตำบลกลับไปยังอำเภอ ต้องไล่ตามลำดับ
📍 ประยุกต์ใช้ใน GIS:
เหมาะกับข้อมูลที่มี ลำดับชั้นชัดเจน เช่น ข้อมูลการปกครอง, การบริหารราชการส่วนภูมิภาค
๒. ฐานข้อมูลแบบเครือข่าย (Network Database)
- โครงสร้างเป็นแบบ กราฟ (Graph Structure)
- หนึ่งระเบียนสามารถมีความสัมพันธ์กับหลายระเบียนทั้ง ระดับบนและล่าง
- รองรับความสัมพันธ์ หลายต่อหลาย (M:N)
📍 ประยุกต์ใช้ใน GIS:
เหมาะกับระบบที่ต้องเชื่อมโยงข้อมูลซ้อน เช่น การจัดการโครงการที่เกี่ยวข้องกับหลายพื้นที่, ระบบโครงข่ายคมนาคม
๓. ฐานข้อมูลเชิงสัมพันธ์ (Relational Database)
- จัดข้อมูลเป็น ตาราง (Table) ที่สามารถเชื่อมโยงกันผ่าน คีย์ร่วม (Key Fields)
- รองรับทั้ง 1:1, 1:N, และ M:N ผ่านตารางกลาง
- มีความยืดหยุ่นสูง ใช้งานร่วมกับ SQL และ GIS software ได้ง่าย
📍 ประยุกต์ใช้ใน GIS:
เป็นโครงสร้างฐานข้อมูล ที่นิยมใช้มากที่สุดในปัจจุบัน โดยเฉพาะในโปรแกรม QGIS, ArcGIS, PostgreSQL/PostGIS เนื่องจากสามารถจัดการข้อมูลเชิงพื้นที่และเชิงตารางได้อย่างมีประสิทธิภาพ และสามารถทำ Spatial Join, Relate, Query ได้อย่างยืดหยุ่น
✅ ตารางสรุปเปรียบเทียบโครงสร้างฐานข้อมูล
| ประเภทฐานข้อมูล | ลักษณะโครงสร้าง | ความสัมพันธ์ | ข้อดี | ข้อจำกัด |
|---|---|---|---|---|
| ลำดับขั้น (Hierarchical) | ต้นไม้ (Tree) | 1:N | ค้นหาแบบลำดับชั้นได้เร็ว | ไม่ยืดหยุ่น เชื่อมโยงข้ามชั้นไม่ได้ |
| เครือข่าย (Network) | กราฟ (Graph) | M:N | เชื่อมโยงข้อมูลได้หลายทิศทาง | ซับซ้อน ใช้งานยากในระบบใหม่ |
| เชิงสัมพันธ์ (Relational) | ตาราง (Table-based) | 1:1, 1:N, M:N | ยืดหยุ่น ใช้ SQL รองรับ GIS software | ต้องมีการออกแบบคีย์ร่วมให้ดี |
๕.๕.๑ ฐานข้อมูลแบบลำดับขั้น (Hierarchical Database)
(Hierarchical Database Structure in GIS)
🔎 ความหมายและลักษณะทั่วไป
ฐานข้อมูลแบบลำดับขั้น (Hierarchical Database) คือรูปแบบการจัดเก็บข้อมูลที่มีลำดับความสัมพันธ์ระหว่างระเบียน (Records) เป็นแบบ “พ่อแม่-ลูก” (Parent–Child) โดยข้อมูลจะถูกจัดเรียงตามลำดับชั้นในโครงสร้างที่คล้ายกับ ต้นไม้หัวกลับ (Inverted Tree Structure)
- ระเบียนระดับบนสุด เรียกว่า Parent Record
- ระเบียนระดับล่าง เรียกว่า Child Record
- หนึ่งระเบียนแม่ (Parent) สามารถมี ลูกหลายระเบียน (Multiple Children)
- แต่หนึ่งระเบียนลูก (Child) จะเชื่อมโยงกับ แม่ได้เพียงหนึ่งเดียว (Single Parent)
โครงสร้างนี้เหมาะกับข้อมูลที่มีความสัมพันธ์ แบบแนวดิ่งและตายตัว เช่น การจัดเก็บข้อมูลในหน่วยงานราชการที่มีลำดับชั้น เช่น จังหวัด → อำเภอ → ตำบล → หมู่บ้าน

รูปที่ 5.10 ฐานข้อมูลแบบลำดับขั้นในระบบ GIS
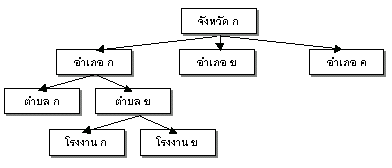
รูปที่ 5.11 โครงสร้างฐานข้อมูลแบบลำดับขั้น
🗺️ การประยุกต์ใช้ในระบบ GIS
ในการประยุกต์ใช้กับระบบสารสนเทศภูมิศาสตร์ (GIS) โครงสร้างแบบลำดับขั้นสามารถใช้ในการจัดการข้อมูลภูมิสารสนเทศที่มีโครงสร้างซ้อนชั้นกันตามลำดับทางภูมิศาสตร์ เช่น:
- จังหวัด → อำเภอ → ตำบล → หมู่บ้าน
- ลุ่มน้ำ → พื้นที่ย่อยลุ่มน้ำ → พื้นที่รับน้ำฝน
- เขตป่า → ป่าไม้ย่อย → พื้นที่ใช้สอยในป่า
🧭 ตัวอย่างการใช้งาน (GIS Context)
หากต้องการสืบค้นว่า “ในอำเภอหนองเสือ (2807) มีโรงงานอะไรบ้าง” ในฐานข้อมูลแบบลำดับขั้น จะต้องดำเนินการแบบเป็นลำดับขั้นดังนี้:
- ค้นหาอำเภอ (Parent): อำเภอหนองเสือ (2807)
- ค้นหาตำบล (Child ของอำเภอ): ตรวจสอบว่ามีตำบลใดบ้างภายใต้อำเภอ
- ค้นหาโรงงาน (Child ของตำบล): ตรวจสอบว่าในแต่ละตำบลมีโรงงานอุตสาหกรรมใดอยู่
📉 ข้อจำกัดในการใช้งาน
การจัดโครงสร้างแบบลำดับขั้นในฐานข้อมูล GIS มีข้อจำกัดที่สำคัญ ได้แก่:
- ไม่รองรับ ความสัมพันธ์แบบกลุ่มต่อกลุ่ม (M:N) หรือการเชื่อมโยงข้ามลำดับชั้น
- การสืบค้นข้อมูลจากลำดับชั้นบนไปชั้นล่างทำได้รวดเร็ว
- แต่หากต้องการสืบค้นข้อมูลที่อยู่ ข้ามระดับกัน จะเกิดความซับซ้อน เช่น:
- ไม่สามารถค้นหาว่า “โรงงานใดบ้างที่อยู่ในอำเภอ X” ได้โดยตรง
- ต้อง ไล่ผ่านตำบลก่อน ทำให้กระบวนการช้า และมี เอนติตี้คั่นกลาง (Intermediate Entity) ที่เพิ่มความซับซ้อน
ตัวอย่างฐานข้อมูลแบบลำดับขั้น (Hierarchical Database) ที่ถูกนำมาใช้จริงในระบบ สารสนเทศภูมิศาสตร์ (GIS) พร้อมคำอธิบายเชิงโครงสร้าง และการประยุกต์ใช้ในงานภูมิสารสนเทศ โดยเน้นให้เข้าใจทั้งระดับทฤษฎีและการใช้งาน:
🗂 ตัวอย่างฐานข้อมูลแบบลำดับขั้นในระบบ GIS
📌 กรณีศึกษา: ระบบการจัดเก็บข้อมูลเขตการปกครอง
✳ โครงสร้างข้อมูล:
textCopyEditจังหวัด (Province)
└── อำเภอ (District)
└── ตำบล (Subdistrict)
└── หมู่บ้าน (Village)
ตารางข้อมูล:
province(Parent)province_id,province_name
district(Child of province)district_id,district_name,province_id
subdistrict(Child of district)subdistrict_id,subdistrict_name,district_id
village(Child of subdistrict)village_id,village_name,subdistrict_id
ทุกระดับมี Primary Key ของตนเอง และมี Foreign Key ที่เชื่อมโยงกับระดับบนหนึ่งระดับเสมอ
ความสัมพันธ์เป็นแบบ One-to-Many ต่อเนื่องเป็นลำดับชั้น (1:N:N:N)
🌍 ประยุกต์ใช้ในงาน GIS
| ระดับข้อมูล | ลักษณะการใช้งาน GIS |
|---|---|
| จังหวัด | การวิเคราะห์เชิงภาพรวม เช่น การใช้ที่ดินระดับจังหวัด |
| อำเภอ | การประมวลผลข้อมูลภายในพื้นที่อำเภอเฉพาะเจาะจง |
| ตำบล | การวิเคราะห์ระดับย่อย เช่น พื้นที่เสี่ยงภัยระดับตำบล |
| หมู่บ้าน | การจัดการทรัพยากรในพื้นที่เฉพาะ เช่น บ่อน้ำประจำหมู่บ้าน |
🔄 ข้อดี:
- ค้นหาแบบลำดับได้เร็ว เช่น “หมู่บ้านนี้อยู่ในอำเภออะไร?”
- เหมาะกับข้อมูลที่ “ไหลจากบนลงล่าง” เช่น งบประมาณจังหวัด → อำเภอ → ตำบล
⚠ ข้อจำกัด:
- หากต้องการสืบค้นแบบข้ามระดับ เช่น “หมู่บ้านนี้อยู่ในจังหวัดอะไร?”
→ ต้องไล่ผ่านตารางsubdistrictและdistrictซึ่งลดประสิทธิภาพในการสืบค้นโดยตรง
📘 ตัวอย่างโครงการจริงที่ใช้ Hierarchical Database
1. ระบบแผนที่ขอบเขตการปกครองของกรมการปกครอง (DOPA GIS)
- โครงสร้างข้อมูลที่ใช้ในการแสดงแผนที่เขตการปกครองของประเทศไทย
- รองรับการสอบถามข้อมูลตั้งแต่ระดับจังหวัดจนถึงหมู่บ้าน
2. ระบบการวางแผนสาธารณสุขระดับตำบล (สปสช.)
- ฐานข้อมูลสุขภาพที่แยกตามตำบลและหมู่บ้าน โดยไล่ลำดับจากจังหวัด
3. GIS ของกรมพัฒนาที่ดิน (LDD Soil Map)
- ข้อมูลชุดดินถูกแบ่งตามระดับพื้นที่: จังหวัด → เขตพัฒนา → พื้นที่สำรวจดิน
🗺️ ตัวอย่างการสอบถามข้อมูลแบบลำดับขั้น (SQL Logic)
sqlCopyEdit-- สอบถามชื่อจังหวัดของหมู่บ้านที่ชื่อว่า "หนองบัว"
SELECT p.province_name
FROM village v
JOIN subdistrict s ON v.subdistrict_id = s.subdistrict_id
JOIN district d ON s.district_id = d.district_id
JOIN province p ON d.province_id = p.province_id
WHERE v.village_name = 'หนองบัว';
สังเกตว่าต้องไล่ความสัมพันธ์ผ่าน 3 ตาราง เพื่อให้ได้ข้อมูลจังหวัด → นี่คือข้อจำกัดสำคัญของ hierarchical model
✅ สรุปเชิงวิเคราะห์
ฐานข้อมูลแบบลำดับขั้นใน GIS ใช้ได้ดีในโครงสร้างภูมิสารสนเทศที่ “เป็นทางเดียว” และไม่ซับซ้อนข้ามระดับ เช่น การบริหารงานท้องถิ่น การจัดสรรทรัพยากรโดยลำดับพื้นที่ แต่ข้อจำกัดคือการสอบถามข้อมูลข้ามลำดับทำได้ไม่สะดวกเท่าฐานข้อมูลเชิงสัมพันธ์ (Relational Database)
ฐานข้อมูลแบบลำดับขั้นเหมาะกับข้อมูลภูมิสารสนเทศที่มีโครงสร้างแนวตั้งแบบชัดเจน เช่น เขตการปกครอง แผนที่การวางแผนของรัฐ เป็นต้น แต่มีข้อจำกัดด้านความยืดหยุ่นของการเชื่อมโยงข้อมูล จึงไม่เหมาะกับกรณีที่ข้อมูลต้องมีการเชื่อมโยงหลายระดับหรือแบบพลวัต เช่น GIS สำหรับวิเคราะห์ภัยพิบัติ หรือความเสี่ยงซ้อนทับหลายปัจจัย
๕.๕.๒ ฐานข้อมูลแบบเครือข่าย (Network Database)
(Network Database Model in GIS Context)
🔎 ความหมายและลักษณะทั่วไป
ฐานข้อมูลแบบเครือข่าย (Network Database) เป็นโครงสร้างการจัดเก็บข้อมูลที่มีลักษณะ ความสัมพันธ์หลายต่อหลาย (Many-to-Many: M:N) ซึ่งแตกต่างจากโครงสร้างแบบลำดับขั้นที่มีความสัมพันธ์แบบหนึ่งต่อกลุ่ม (1:N) เท่านั้น โดยในแบบเครือข่าย:
“ระเบียนหนึ่งสามารถมีความสัมพันธ์กับระเบียนอื่นได้หลายระเบียน ทั้งในแนวตั้ง แนวนอน หรือข้ามลำดับชั้น”
ลักษณะของโครงสร้างจะคล้าย กราฟ (Graph Structure) ที่ไม่มีการจำกัดทิศทางความสัมพันธ์ และไม่มีข้อจำกัดในลำดับของข้อมูล ทำให้การเชื่อมโยงระหว่างข้อมูล มีความยืดหยุ่นและประสิทธิภาพสูงในการสืบค้น
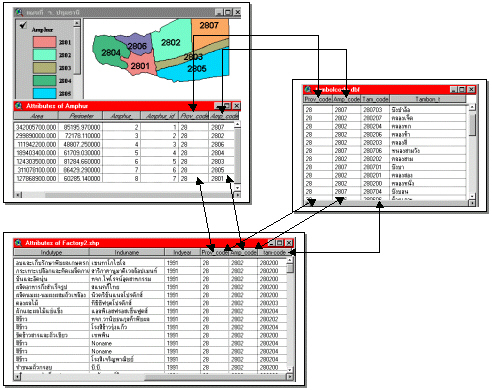
รูปที่ 5.12 แสดงฐานข้อมูลแบบเครือข่าย
🧭 ตัวอย่างการใช้งานในระบบ GIS
🗺️ กรณีศึกษา: ข้อมูลแหล่งน้ำกับการใช้ที่ดิน
| ตารางข้อมูล | ความสัมพันธ์ |
|---|---|
land_use | แปลงที่ดินที่สามารถใช้เพื่อการเกษตร/อุตสาหกรรม |
water_source | แหล่งน้ำหลายประเภท เช่น แม่น้ำ อ่างเก็บน้ำ |
land_water_link | ตารางกลางที่แสดงว่าแหล่งน้ำใดให้บริการพื้นที่ใด |
ในระบบนี้:
- แหล่งน้ำหนึ่งอาจให้บริการหลายพื้นที่การใช้ที่ดิน
- พื้นที่การใช้ที่ดินหนึ่งอาจมีแหล่งน้ำมากกว่าหนึ่งแห่งให้บริการ
นี่คือความสัมพันธ์แบบ Many-to-Many (M:N) ซึ่งเป็นลักษณะสำคัญของ ฐานข้อมูลแบบเครือข่าย
🔗 เปรียบเทียบกับโครงสร้างแบบลำดับขั้น
| ประเด็นเปรียบเทียบ | ฐานข้อมูลแบบลำดับขั้น | ฐานข้อมูลแบบเครือข่าย |
|---|---|---|
| ความยืดหยุ่นของโครงสร้าง | ต่ำ | สูง |
| ความสัมพันธ์ข้ามลำดับชั้น | ไม่รองรับ | รองรับ |
| ความสามารถในการ Join หลายข้อมูล | จำกัด | ครอบคลุม |
| การใช้งานใน GIS | เขตการปกครอง | ระบบโครงข่าย, สาธารณูปโภค |
✅ จุดเด่นของฐานข้อมูลแบบเครือข่าย
- รองรับการ วิเคราะห์โครงข่าย (Network Analysis) ได้ดี เช่น:
- การไหลของน้ำ
- การคมนาคมขนส่ง (ถนน, รถไฟ, เส้นทางขนส่งสินค้า)
- การกระจายสาธารณูปโภค (ไฟฟ้า, น้ำประปา)
- สืบค้นข้อมูลแบบ ย้อนกลับ หรือ ข้ามชั้น ได้อย่างยืดหยุ่น เช่น:
- “แหล่งน้ำใดให้บริการแก่พื้นที่เกษตรหลายประเภท?”
- “แปลงที่ดินใดได้รับผลกระทบจากการเปลี่ยนแปลงคุณภาพน้ำ?”
⚠ ข้อควรระวังในการออกแบบ
- โครงสร้างแบบเครือข่ายมีความซับซ้อนสูง
- ควรมีการออกแบบ Entity-Relationship Diagram (ERD) อย่างชัดเจน
- ต้องจัดการความสัมพันธ์ด้วย ตารางกลาง (Link Table) เพื่อควบคุมข้อมูลไม่ให้ซ้ำซ้อน
📘 ตัวอย่างระบบ GIS ที่ใช้ฐานข้อมูลแบบเครือข่าย
- ระบบวิเคราะห์โครงข่ายถนน (Transportation GIS)
- เช่น ArcGIS Network Analyst, pgRouting (PostGIS Extension)
- ระบบติดตามแหล่งน้ำและการชลประทาน
- เช่น การวิเคราะห์การกระจายน้ำจากอ่างเก็บน้ำไปยังพื้นที่เกษตร
- ระบบติดตามไฟฟ้า/พลังงาน (Utility GIS)
- การวางสายส่งที่ต้องสัมพันธ์กับหลายหม้อแปลงและพื้นที่บริการ
🔚 บทสรุป
ฐานข้อมูลแบบเครือข่ายในระบบ GIS เป็นโครงสร้างที่เหมาะกับระบบที่มีความเชื่อมโยงแบบซับซ้อน และต้องการประสิทธิภาพในการสอบถามข้อมูลที่ไม่ได้เป็นแบบลำดับขั้น เช่น การคำนวณเส้นทาง, การไหลของทรัพยากร และการเชื่อมโยงข้อมูลหลายแหล่งพร้อมกัน
ตัวอย่างฐานข้อมูลแบบเครือข่าย (Network Database) ที่ใช้ในระบบ สารสนเทศภูมิศาสตร์ (Geographic Information Systems – GIS) มีหลากหลาย โดยเฉพาะในงานที่ต้องอาศัยโครงสร้างความสัมพันธ์ที่ซับซ้อนแบบ Many-to-Many (M:N) หรือแบบที่ต้องวิเคราะห์การเชื่อมโยง เช่น การไหล การเชื่อมต่อ การเดินทาง ฯลฯ
ด้านล่างคือตัวอย่างเชิงโครงสร้าง พร้อมการประยุกต์ใช้จริงในระบบ GIS:
🧭 ตัวอย่าง 1: ระบบวิเคราะห์เครือข่ายถนน (Road Network Analysis)
📊 โครงสร้างฐานข้อมูล
| ตาราง (Entity) | รายละเอียด |
|---|---|
road_segment | ข้อมูลเส้นถนน → แต่ละ segment มีรหัส, geometry, ความเร็ว |
intersection | จุดตัดของถนน → ใช้เป็น Node สำหรับเชื่อมโยง |
road_type | ประเภทของถนน (หลัก, รอง, ลูกรัง ฯลฯ) |
road_segment_type_link | ตารางกลาง (M:N) ระหว่างถนนกับประเภทถนน |
🔗 ความสัมพันธ์แบบเครือข่าย
- 1 จุดตัด (intersection) เชื่อมโยง หลายถนน
- 1 ถนน อาจมีหลายประเภท (บางช่วงเป็นถนนหลัก บางช่วงลูกรัง)
- ความสัมพันธ์เป็นแบบ กลุ่มต่อกลุ่ม (M:N) และ มี node–edge topology
🗺️ การประยุกต์ใน GIS
- การหาทางลัด, การคำนวณเวลาเดินทาง, การค้นหาเส้นทางสั้นสุด (Shortest Path)
- ใช้ใน ArcGIS Network Analyst, QGIS + pgRouting
🌾 ตัวอย่าง 2: ระบบโครงข่ายแหล่งน้ำและการชลประทาน
📊 โครงสร้างฐานข้อมูล
| ตารางหลัก | รายละเอียด |
|---|---|
canal | เส้นทางคลองส่งน้ำ |
reservoir | อ่างเก็บน้ำต้นทาง |
farm_plot | แปลงเกษตรกรรมที่รับน้ำ |
water_supply_link | ตารางกลางเชื่อมอ่างเก็บน้ำ → คลอง → แปลงเกษตร |
🔗 ความสัมพันธ์
- 1 อ่างเก็บน้ำ → หลายคลอง
- 1 คลอง → หลายแปลง
- 1 แปลงอาจรับน้ำจากหลายคลอง
→ เกิด ความสัมพันธ์แบบเครือข่ายหลายทิศทาง
🗺️ การประยุกต์ใน GIS
- วิเคราะห์พื้นที่ที่รับน้ำจากโครงการชลประทาน
- ตรวจสอบผลกระทบจากการปิดเขื่อนบางแห่งต่อพื้นที่เพาะปลูก
- ใช้ใน ระบบ LDD GIS ของกรมพัฒนาที่ดิน หรือ Irrigation GIS ของกรมชลประทาน
⚡ ตัวอย่าง 3: ระบบไฟฟ้าและสาธารณูปโภค (Utility GIS)
📊 โครงสร้างฐานข้อมูล
| ตารางหลัก | รายละเอียด |
|---|---|
transformer | หม้อแปลงไฟฟ้า |
power_line | สายส่งไฟฟ้า |
consumer | ผู้ใช้บริการ |
power_distribution_link | ตารางกลางเชื่อมสายไฟกับหม้อแปลงและผู้ใช้ |
🧠 ความสัมพันธ์แบบ M:N
- 1 หม้อแปลงจ่ายไฟให้หลายสายไฟ
- 1 สายไฟเชื่อมกับหลายหม้อแปลง
- 1 ผู้ใช้รับไฟจากหลายสาย
→ โครงสร้างนี้จำเป็นต้องใช้ฐานข้อมูลแบบ Network หรือ Relational-M:N
🗺️ การประยุกต์ใน GIS
- ตรวจสอบผลกระทบจากไฟฟ้าขัดข้อง
- วิเคราะห์ความหนาแน่นของผู้ใช้ไฟฟ้า
- ใช้ใน ระบบ EGAT GIS หรือ MEA Smart Grid GIS
✅ สรุปเชิงเปรียบเทียบ
| ด้าน | ลำดับขั้น (Hierarchical) | เครือข่าย (Network) | เชิงสัมพันธ์ (Relational) |
|---|---|---|---|
| ความสัมพันธ์ข้อมูล | 1:N | M:N, 1:N, 1:1 | 1:N, M:N, Flexible |
| ความซับซ้อน | น้อย | สูง | ปานกลาง |
| เหมาะกับงาน | เขตการปกครอง | โครงข่าย, พลังงาน, คมนาคม | ข้อมูลทั่วไป, แบบสอบถาม, สถิติ |
| ตัวอย่าง | จังหวัด → อำเภอ | ถนน, คลอง, ไฟฟ้า | ที่ดินกับข้อมูลสังคม |
๕.๕.๓ ฐานข้อมูลแบบเชิงสัมพันธ์ (Relational Database)
(Relational Database in GIS Applications)
🔎 ความหมายและโครงสร้างพื้นฐาน
ฐานข้อมูลเชิงสัมพันธ์ (Relational Database) คือรูปแบบการจัดเก็บข้อมูลที่มีการแบ่งข้อมูลออกเป็น ตาราง (Table) ซึ่งเป็นหน่วยเก็บข้อมูลหลัก โดยตารางหนึ่ง ๆ ประกอบด้วย:
- แถว (Row) หรือ ระเบียน (Record) ซึ่งแทนแต่ละรายการของข้อมูล
- คอลัมน์ (Column) หรือ เขตข้อมูล (Field) ซึ่งระบุคุณลักษณะของข้อมูลแต่ละรายการ
ระบบฐานข้อมูลเชิงสัมพันธ์สามารถจัดการข้อมูลได้อย่างมีประสิทธิภาพ โดยอาศัยแนวคิดในการ เชื่อมโยง (Relate) หรือ เชื่อมตาราง (Join) ผ่าน คีย์ (Key Field) ที่เป็นเขตข้อมูลร่วมกันของหลายตาราง เช่น รหัสหมู่บ้าน, รหัสตำบล, หรือรหัสประเภทที่ดิน
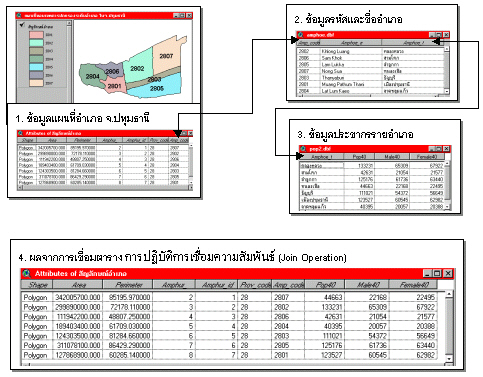
รูปที่ 5.13 แสดงฐานข้อมูลแบบเชิงสัมพันธ์
🗺️ การประยุกต์ใช้ในระบบสารสนเทศภูมิศาสตร์ (GIS)
ในระบบ GIS ข้อมูลมักถูกแบ่งเป็น 2 ประเภทหลัก:
- ข้อมูลเชิงพื้นที่ (Spatial Data): เก็บอยู่ในตารางพิเศษที่มีข้อมูลพิกัด เช่น
geometry,geom, หรือshape - ข้อมูลเชิงคุณลักษณะ (Attribute Data): เก็บอยู่ในตารางอื่น ๆ ที่สามารถเชื่อมโยงกับข้อมูลเชิงพื้นที่ผ่านคีย์ เช่น รหัสหมู่บ้าน, ประเภทพื้นที่
📍 ตัวอย่างการเชื่อมตารางใน GIS:
sqlCopyEditSELECT
landuse.geom,
landuse.plot_id,
owner.name,
owner.phone
FROM
landuse
JOIN
owner ON landuse.owner_id = owner.owner_id;
🔗 การปฏิบัติการเชื่อมความสัมพันธ์ (Join Operation)
การ Join ตารางสามารถทำได้หลายประเภท เช่น:
- Inner Join: แสดงเฉพาะข้อมูลที่มีความสัมพันธ์ตรงกันทั้งสองตาราง
- Left Join: แสดงข้อมูลทั้งหมดของตารางซ้าย และเฉพาะข้อมูลที่ตรงกันจากตารางขวา
- Relate: ใช้ใน GIS เพื่อแสดงความสัมพันธ์โดยไม่รวมข้อมูลเป็นตารางเดียว
การเชื่อมข้อมูลแบบเชิงสัมพันธ์นี้เป็นหัวใจสำคัญของระบบ GIS เนื่องจาก:
- ช่วยให้สามารถวิเคราะห์ข้อมูลหลายมิติได้ เช่น การใช้ที่ดิน + จำนวนประชากร
- ลดการซ้ำซ้อนของข้อมูล
- เพิ่มความยืดหยุ่นในการสอบถามข้อมูลเฉพาะเจาะจง
✅ ข้อดีของฐานข้อมูลเชิงสัมพันธ์ในระบบ GIS
| ข้อดี | คำอธิบาย |
|---|---|
| ความยืดหยุ่นสูง | สามารถจัดการความสัมพันธ์ได้หลากหลายแบบ (1:1, 1:N, M:N) |
| รองรับการ Query ขั้นสูง | เช่น การคำนวณเชิงพื้นที่ (Spatial Query), การวิเคราะห์ซ้อนชั้นข้อมูล |
| ประหยัดพื้นที่จัดเก็บ | โดยไม่ต้องเก็บข้อมูลซ้ำในทุกตาราง |
| เพิ่มประสิทธิภาพ | โดยเฉพาะเมื่อใช้ร่วมกับ RDBMS เช่น PostgreSQL/PostGIS, SQLite/SpatiaLite, MS SQL Server |
⚠ ข้อควรพิจารณา
แม้ว่าการรวมข้อมูลที่เกี่ยวข้องไว้ในตารางเดียวจะช่วยให้เรียกใช้งานได้เร็วขึ้น แต่ในเชิงโครงสร้างแล้ว:
- หากข้อมูลมีขนาดใหญ่ หรือซ้ำซ้อนมาก อาจทำให้ฐานข้อมูลมีขนาดใหญ่เกินจำเป็น
- การ Normalize ตาราง (แยกตารางตามประเภทข้อมูลและความสัมพันธ์) เป็นแนวทางที่นิยม เพื่อให้ฐานข้อมูลมีความยั่งยืนและขยายต่อได้ง่าย
🧭 โปรแกรมฐานข้อมูลเชิงสัมพันธ์ยอดนิยมใน GIS
| ชื่อระบบ | จุดเด่น | รองรับ GIS |
|---|---|---|
| PostgreSQL + PostGIS | รองรับ spatial index, topology | ✅ |
| SQLite + SpatiaLite | ขนาดเบา, ใช้งานใน QGIS | ✅ |
| MS SQL Server | ใช้ในองค์กรขนาดใหญ่ | ✅ |
| MySQL | ใช้งานทั่วไป, Spatial limited | ❌ (จำกัด GIS Functions) |
🔚 สรุป
ฐานข้อมูลแบบเชิงสัมพันธ์เป็นโครงสร้างที่มีความยืดหยุ่นสูง เหมาะกับการจัดการข้อมูล GIS ที่มีลักษณะเชื่อมโยงกันหลากหลาย การใช้คีย์ร่วมเพื่อเชื่อมตารางช่วยให้การสอบถามข้อมูล (Query) และการวิเคราะห์เชิงพื้นที่ (Spatial Analysis) มีประสิทธิภาพและสามารถขยายระบบได้ในระยะยาว
ตัวอย่างฐานข้อมูลแบบเชิงสัมพันธ์ (Relational Database) ที่ใช้จริงในระบบ สารสนเทศภูมิศาสตร์ (GIS) โดยเน้นที่ความสัมพันธ์ระหว่างตารางข้อมูลเชิงพื้นที่ (Spatial) และตารางข้อมูลเชิงคุณลักษณะ (Attribute) ซึ่งช่วยเพิ่มประสิทธิภาพในการวิเคราะห์ข้อมูลเชิงพื้นที่ได้อย่างยืดหยุ่น:
🧭 ตัวอย่างที่ 1: ระบบแผนที่แปลงเกษตรกับข้อมูลเกษตรกร
🎯 ระบบ: กรมส่งเสริมการเกษตร (DOAE GIS)
🗂 โครงสร้างฐานข้อมูล:
| ชื่อตาราง | เนื้อหาข้อมูล |
|---|---|
farm_plot | ข้อมูลแปลงที่ดิน (เชิงพื้นที่ Polygon) |
farmer | ข้อมูลเกษตรกร เช่น ชื่อ อายุ สังกัดหมู่บ้าน |
crop_type | รหัสและชนิดพืชที่ปลูก เช่น ข้าว มันสำปะหลัง |
plot_crop_link | ตารางกลางเชื่อม farm_plot กับ crop_type |
🔗 ความสัมพันธ์เชิงสัมพันธ์:
- 1 เกษตรกร สามารถมีหลายแปลง (1:N)
- 1 แปลง อาจปลูกพืชได้หลายชนิด (M:N)
- ตาราง
plot_crop_linkทำหน้าที่เป็น ตารางความสัมพันธ์แบบกลุ่มต่อกลุ่ม (M:N)
🏞 ตัวอย่างที่ 2: ระบบข้อมูลที่ดินและสิ่งปลูกสร้าง
🎯 ระบบ: กรมที่ดิน – e-Land GIS
🗂 โครงสร้างฐานข้อมูล:
| ชื่อตาราง | รายละเอียด |
|---|---|
land_parcel | ข้อมูลแปลงที่ดิน (polygon) |
owner | ข้อมูลเจ้าของที่ดิน เช่น ชื่อ นามสกุล รหัสบัตร |
building | ข้อมูลสิ่งปลูกสร้างในแต่ละแปลงที่ดิน |
parcel_owner_link | ตารางกลางเชื่อมเจ้าของกับแปลงที่ดิน (M:N) |
📍 ตัวอย่างการเชื่อม:
sqlCopyEditSELECT lp.parcel_id, o.name, b.building_type
FROM land_parcel lp
JOIN parcel_owner_link pl ON lp.parcel_id = pl.parcel_id
JOIN owner o ON pl.owner_id = o.owner_id
JOIN building b ON lp.parcel_id = b.parcel_id;
🚧 ตัวอย่างที่ 3: ระบบจัดการโครงสร้างพื้นฐานถนนเทศบาล
🎯 ระบบ: เทศบาลตำบลเมืองแสนสุข (Municipal GIS)
🗂 โครงสร้างฐานข้อมูล:
| ตาราง | รายละเอียด |
|---|---|
road_network | ข้อมูลสายถนน (Line Geometry) |
road_condition | รหัสสภาพถนน (ดี, พัง, ปรับปรุง ฯลฯ) |
maintenance_log | ประวัติการซ่อมบำรุงถนนแต่ละสาย |
🔗 ความสัมพันธ์:
- 1 ถนน → หลายเหตุการณ์ซ่อมบำรุง (1:N)
- ตาราง
road_conditionเชื่อมกับroad_networkผ่านรหัสสภาพ
🧑⚕️ ตัวอย่างที่ 4: ระบบสนับสนุนบริการสาธารณสุขระดับตำบล
🎯 ระบบ: สำนักงานหลักประกันสุขภาพแห่งชาติ (สปสช.)
| ตาราง | รายละเอียด |
|---|---|
health_facility | ตำแหน่งสถานพยาบาล (Point) |
village | ข้อมูลหมู่บ้าน (Polygon) |
population | จำนวนประชากรในหมู่บ้าน |
facility_village | ตารางความเชื่อมโยงการให้บริการ (M:N) |
🧠 ความสัมพันธ์:
- 1 สถานพยาบาลให้บริการหลายหมู่บ้าน (1:N)
- หมู่บ้านอาจได้รับบริการจากหลายสถานพยาบาล (M:N)
✅ สรุป: ลักษณะเด่นของฐานข้อมูลเชิงสัมพันธ์ใน GIS
| จุดเด่น | ผลประโยชน์ |
|---|---|
| ควบคุมข้อมูลได้ง่าย | แต่ละตารางมีเนื้อหาชัดเจน ไม่ซ้ำซ้อน |
| สืบค้นและวิเคราะห์ได้แม่นยำ | ใช้ Join, Relate, Spatial Query ได้เต็มที่ |
| รองรับโครงสร้างซับซ้อน | เช่น การใช้ตารางกลางสำหรับ M:N |
| ขยายข้อมูลในอนาคตได้ง่าย | เพิ่มแอตทริบิวต์หรือตารางใหม่ได้โดยไม่กระทบระบบเดิม |
ER Diagram: Agricultural GIS Database
ภาพด้านบนคือ ER Diagram สำหรับระบบฐานข้อมูลทางการเกษตร (Agricultural GIS Database) ซึ่งแสดงความสัมพันธ์เชิงโครงสร้างของข้อมูลเชิงพื้นที่และข้อมูลเชิงคุณลักษณะในบริบทของ ระบบสารสนเทศภูมิศาสตร์ (GIS) ดังนี้:
🔹 โครงสร้างตารางและความสัมพันธ์
| Entity | คำอธิบาย |
|---|---|
| Farmer | ข้อมูลเกษตรกร เช่น ชื่อ รหัสเกษตรกร |
| Farm_Plot | แปลงเกษตรกรรม (Polygon) |
| Crop_Type | ชนิดพืชที่ปลูก เช่น ข้าว อ้อย ข้าวโพด |
| Plot_Crop_Link | ตารางกลางเชื่อมหลายแปลงกับหลายชนิดพืช (M:N) |
| Soil_Type | ข้อมูลชนิดของดินในแต่ละแปลง |
| Irrigation | ข้อมูลแหล่งน้ำหรือระบบชลประทาน |
🔗 ความสัมพันธ์หลัก
- เกษตรกรหนึ่งคน (Farmer) → มีได้หลายแปลง (Farm_Plot)
- แปลงหนึ่งแปลง → ปลูกพืชได้หลายชนิด (Crop_Type) ผ่านตารางกลาง (Plot_Crop_Link)
- แปลงหนึ่ง → มีดินชนิดเดียวหรือหลายชนิด (Soil_Type)
- แปลงหนึ่ง → ใช้น้ำจากระบบชลประทานหนึ่งหรือหลายระบบ (Irrigation)
ER Diagram: Road Network GIS Database
ภาพด้านบนแสดง ER Diagram สำหรับระบบฐานข้อมูลโครงข่ายถนน (Road Network GIS Database) ซึ่งออกแบบในเชิง GIS โดยมีโครงสร้างที่เหมาะสมกับการจัดเก็บและวิเคราะห์ข้อมูลโครงข่ายการคมนาคมและสาธารณูปโภค:
🔍 อธิบายแต่ละ Entity และความสัมพันธ์
| Entity | คำอธิบาย |
|---|---|
| Road_Segment | ข้อมูลเส้นถนนแต่ละช่วง (Polyline Geometry) |
| Intersection | จุดตัดถนน หรือจุดเชื่อมระหว่างถนนหลายสาย |
| Road_Type | ประเภทของถนน เช่น ทางหลวง, ถนนชุมชน |
| Maintenance_Log | ประวัติการซ่อมบำรุงถนน เช่น วันที่ซ่อม, รายการงาน |
| Traffic_Volume | ปริมาณการจราจร เช่น จำนวนรถต่อวัน |
| Speed_Limit_Zone | ข้อมูลพื้นที่จำกัดความเร็ว เช่น 30, 50, 80 km/h |
🔗 ความสัมพันธ์
- แต่ละ Road_Segment เชื่อมกับ Intersection 2 จุด (เริ่ม–สิ้นสุด)
- Road_Segment มีประเภทที่กำหนดไว้ใน Road_Type
- มีการบันทึกประวัติซ่อมบำรุงใน Maintenance_Log
- อาจมีข้อมูลจราจรใน Traffic_Volume
- อยู่ในเขตจำกัดความเร็วตาม Speed_Limit_Zone
🧭 การประยุกต์ใช้ในระบบ GIS
- วิเคราะห์เส้นทางที่มีการจราจรหนาแน่น
- วางแผนซ่อมบำรุง
- ใช้ร่วมกับ Network Analyst ใน ArcGIS หรือ pgRouting ใน PostGIS
- เชื่อมโยงกับ Smart City Dashboard หรือ Mobile Map Apps